
Machine Learning Hypothesis Testing Project
Data Analysis
Planning for data analysis
- Preparing/collecting the data
- Undertanding data
- Exploring data insights
- Data Cleansing
- Feature selection
- Creating model
- Fit data to the model
- Evaluate the model
- Fine tune the model
## required packages
import pandas as pd
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
DATA_DIR='data/'
# Load Excel dataset for analysis. I will use pandas library to work with it.
def load_data(file_name,sheet):
return pd.read_excel(os.path.join(DATA_DIR,file_name), sheet, index_col=None)
control_data=load_data('UdacityABtesting.xlsx','Control')
print(control_data.shape)
experment_data=load_data('UdacityABtesting.xlsx','Experiment')
print(experment_data.shape)
(37, 5)
(37, 5)
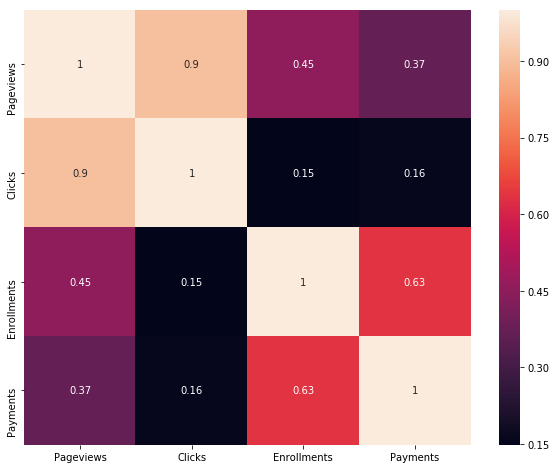
corr = control_data.corr()
f, ax = plt.subplots(figsize=(10, 8))
sns.heatmap(corr,annot=True,
xticklabels=corr.columns.values,
yticklabels=corr.columns.values)
<matplotlib.axes._subplots.AxesSubplot at 0x21f84888668>
corr = experment_data.corr()
f, ax = plt.subplots(figsize=(10, 8))
sns.heatmap(corr,annot=True,
xticklabels=corr.columns.values,
yticklabels=corr.columns.values)
<matplotlib.axes._subplots.AxesSubplot at 0x21f84dfbb38>
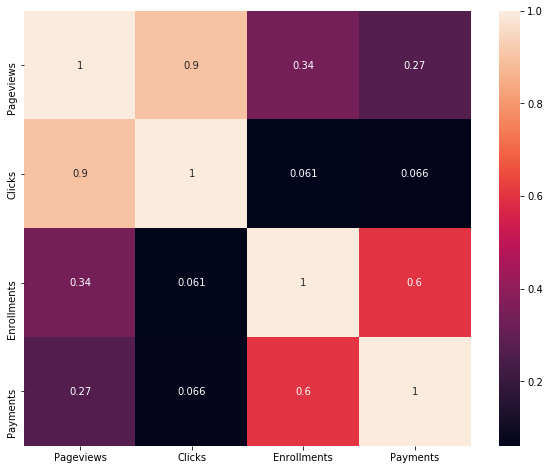
For both Control and Experment data, Payment feature is highly correlated (63% Control, 60% Experiment) to the target feature Enrollment. This shows that payment is very critical for enrollment prediction. Explain what the difference is between using A/B testing to test a hypothesis (in this case showing a message window) vs using - Machine learning to learn the viability of the same effect?
Data analysis tasks
##investigating the data
experment_data.head()
| Date | Pageviews | Clicks | Enrollments | Payments | |
|---|---|---|---|---|---|
| 0 | Sat, Oct 11 | 7716 | 686 | 105.0 | 34.0 |
| 1 | Sun, Oct 12 | 9288 | 785 | 116.0 | 91.0 |
| 2 | Mon, Oct 13 | 10480 | 884 | 145.0 | 79.0 |
| 3 | Tue, Oct 14 | 9867 | 827 | 138.0 | 92.0 |
| 4 | Wed, Oct 15 | 9793 | 832 | 140.0 | 94.0 |
control_data.head()
| Date | Pageviews | Clicks | Enrollments | Payments | |
|---|---|---|---|---|---|
| 0 | Sat, Oct 11 | 7723 | 687 | 134.0 | 70.0 |
| 1 | Sun, Oct 12 | 9102 | 779 | 147.0 | 70.0 |
| 2 | Mon, Oct 13 | 10511 | 909 | 167.0 | 95.0 |
| 3 | Tue, Oct 14 | 9871 | 836 | 156.0 | 105.0 |
| 4 | Wed, Oct 15 | 10014 | 837 | 163.0 | 64.0 |
control_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 37 entries, 0 to 36
Data columns (total 5 columns):
Date 37 non-null object
Pageviews 37 non-null int64
Clicks 37 non-null int64
Enrollments 23 non-null float64
Payments 23 non-null float64
dtypes: float64(2), int64(2), object(1)
memory usage: 1.5+ KB
experment_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 37 entries, 0 to 36
Data columns (total 5 columns):
Date 37 non-null object
Pageviews 37 non-null int64
Clicks 37 non-null int64
Enrollments 23 non-null float64
Payments 23 non-null float64
dtypes: float64(2), int64(2), object(1)
memory usage: 1.5+ KB
Both experment and control has total of 5 columns and 37 enteries. Interms of feature distribution both experment and control data has 4 continous and 1 categorical(i.e date column) feature. Moreover, Enrollments and Payments column has only 23 non-null features values out of 37. So, we need to invetigate on this later.
Lets inspect which rows data is missed.
experment_data.loc[experment_data['Enrollments'].isnull()]
| Date | Pageviews | Clicks | Enrollments | Payments | |
|---|---|---|---|---|---|
| 23 | Mon, Nov 3 | 9359 | 789 | NaN | NaN |
| 24 | Tue, Nov 4 | 9427 | 743 | NaN | NaN |
| 25 | Wed, Nov 5 | 9633 | 808 | NaN | NaN |
| 26 | Thu, Nov 6 | 9842 | 831 | NaN | NaN |
| 27 | Fri, Nov 7 | 9272 | 767 | NaN | NaN |
| 28 | Sat, Nov 8 | 8969 | 760 | NaN | NaN |
| 29 | Sun, Nov 9 | 9697 | 850 | NaN | NaN |
| 30 | Mon, Nov 10 | 10445 | 851 | NaN | NaN |
| 31 | Tue, Nov 11 | 9931 | 831 | NaN | NaN |
| 32 | Wed, Nov 12 | 10042 | 802 | NaN | NaN |
| 33 | Thu, Nov 13 | 9721 | 829 | NaN | NaN |
| 34 | Fri, Nov 14 | 9304 | 770 | NaN | NaN |
| 35 | Sat, Nov 15 | 8668 | 724 | NaN | NaN |
| 36 | Sun, Nov 16 | 8988 | 710 | NaN | NaN |
control_data.loc[control_data['Enrollments'].isnull()]
| Date | Pageviews | Clicks | Enrollments | Payments | |
|---|---|---|---|---|---|
| 23 | Mon, Nov 3 | 9437 | 788 | NaN | NaN |
| 24 | Tue, Nov 4 | 9420 | 781 | NaN | NaN |
| 25 | Wed, Nov 5 | 9570 | 805 | NaN | NaN |
| 26 | Thu, Nov 6 | 9921 | 830 | NaN | NaN |
| 27 | Fri, Nov 7 | 9424 | 781 | NaN | NaN |
| 28 | Sat, Nov 8 | 9010 | 756 | NaN | NaN |
| 29 | Sun, Nov 9 | 9656 | 825 | NaN | NaN |
| 30 | Mon, Nov 10 | 10419 | 874 | NaN | NaN |
| 31 | Tue, Nov 11 | 9880 | 830 | NaN | NaN |
| 32 | Wed, Nov 12 | 10134 | 801 | NaN | NaN |
| 33 | Thu, Nov 13 | 9717 | 814 | NaN | NaN |
| 34 | Fri, Nov 14 | 9192 | 735 | NaN | NaN |
| 35 | Sat, Nov 15 | 8630 | 743 | NaN | NaN |
| 36 | Sun, Nov 16 | 8970 | 722 | NaN | NaN |
For both control and experment data, target column Enrollments is missed for entries after November 3. So, thee only option we have is droping all with null values.
##Merging two DataFrames
data = control_data.append(experment_data, ignore_index=True)
data.shape
(74, 5)
dummy=[0] * 74
data.insert(1, 'id',dummy)
data.loc[data.Enrollments.isin(experment_data.Enrollments), 'id'] = 1
data.tail(10)##because appended rows are at last position
| Date | id | Pageviews | Clicks | Enrollments | Payments | |
|---|---|---|---|---|---|---|
| 64 | Fri, Nov 7 | 1 | 9272 | 767 | NaN | NaN |
| 65 | Sat, Nov 8 | 1 | 8969 | 760 | NaN | NaN |
| 66 | Sun, Nov 9 | 1 | 9697 | 850 | NaN | NaN |
| 67 | Mon, Nov 10 | 1 | 10445 | 851 | NaN | NaN |
| 68 | Tue, Nov 11 | 1 | 9931 | 831 | NaN | NaN |
| 69 | Wed, Nov 12 | 1 | 10042 | 802 | NaN | NaN |
| 70 | Thu, Nov 13 | 1 | 9721 | 829 | NaN | NaN |
| 71 | Fri, Nov 14 | 1 | 9304 | 770 | NaN | NaN |
| 72 | Sat, Nov 15 | 1 | 8668 | 724 | NaN | NaN |
| 73 | Sun, Nov 16 | 1 | 8988 | 710 | NaN | NaN |
# # convert the 'Date' column to datetime format and append new column that holds weekday
data['Date'] = pd.to_datetime(data['Date'],format='%a, %b %d', errors='ignore')
data.insert(2,'day_of_week',data['Date'].dt.weekday)
##shuffle rows using sklearn utils package to control data leakage
import sklearn
data = sklearn.utils.shuffle(data)
##add column named row_id to hold index of entries
data.insert(0,'row_id',range(1, len(data) + 1))
data.set_index('row_id')
| Date | id | day_of_week | Pageviews | Clicks | Enrollments | Payments | |
|---|---|---|---|---|---|---|---|
| row_id | |||||||
| 1 | 1900-11-08 | 1 | 3 | 9010 | 756 | NaN | NaN |
| 2 | 1900-10-21 | 0 | 6 | 10660 | 867 | 196.0 | 105.0 |
| 3 | 1900-11-15 | 1 | 3 | 8668 | 724 | NaN | NaN |
| 4 | 1900-10-14 | 1 | 6 | 9867 | 827 | 138.0 | 92.0 |
| 5 | 1900-10-17 | 0 | 2 | 9008 | 748 | 146.0 | 76.0 |
| 6 | 1900-10-22 | 1 | 0 | 9947 | 838 | 162.0 | 92.0 |
| 7 | 1900-11-13 | 1 | 1 | 9717 | 814 | NaN | NaN |
| 8 | 1900-11-06 | 1 | 1 | 9921 | 830 | NaN | NaN |
| 9 | 1900-10-12 | 0 | 4 | 9102 | 779 | 147.0 | 70.0 |
| 10 | 1900-11-07 | 1 | 2 | 9272 | 767 | NaN | NaN |
| 11 | 1900-10-23 | 1 | 1 | 8176 | 642 | 122.0 | 68.0 |
| 12 | 1900-11-08 | 1 | 3 | 8969 | 760 | NaN | NaN |
| 13 | 1900-10-16 | 1 | 1 | 9670 | 823 | 138.0 | 82.0 |
| 14 | 1900-11-09 | 1 | 4 | 9656 | 825 | NaN | NaN |
| 15 | 1900-11-03 | 1 | 5 | 9359 | 789 | NaN | NaN |
| 16 | 1900-10-29 | 1 | 0 | 9262 | 727 | 201.0 | 96.0 |
| 17 | 1900-11-13 | 1 | 1 | 9721 | 829 | NaN | NaN |
| 18 | 1900-10-30 | 1 | 1 | 9308 | 728 | 207.0 | 67.0 |
| 19 | 1900-11-07 | 1 | 2 | 9424 | 781 | NaN | NaN |
| 20 | 1900-11-16 | 1 | 4 | 8970 | 722 | NaN | NaN |
| 21 | 1900-11-12 | 1 | 0 | 10134 | 801 | NaN | NaN |
| 22 | 1900-11-03 | 1 | 5 | 9437 | 788 | NaN | NaN |
| 23 | 1900-10-30 | 0 | 1 | 9345 | 734 | 167.0 | 75.0 |
| 24 | 1900-11-04 | 1 | 6 | 9420 | 781 | NaN | NaN |
| 25 | 1900-11-01 | 1 | 3 | 8448 | 695 | 142.0 | 100.0 |
| 26 | 1900-10-11 | 0 | 3 | 7723 | 687 | 134.0 | 70.0 |
| 27 | 1900-10-19 | 1 | 4 | 8434 | 697 | 120.0 | 77.0 |
| 28 | 1900-11-01 | 0 | 3 | 8460 | 681 | 156.0 | 93.0 |
| 29 | 1900-10-28 | 0 | 6 | 9363 | 736 | 154.0 | 91.0 |
| 30 | 1900-10-26 | 1 | 4 | 8881 | 693 | 153.0 | 101.0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 45 | 1900-10-13 | 1 | 5 | 10480 | 884 | 145.0 | 79.0 |
| 46 | 1900-11-10 | 1 | 5 | 10419 | 874 | NaN | NaN |
| 47 | 1900-11-15 | 1 | 3 | 8630 | 743 | NaN | NaN |
| 48 | 1900-10-24 | 0 | 2 | 9434 | 673 | 220.0 | 122.0 |
| 49 | 1900-10-21 | 1 | 6 | 10551 | 864 | 143.0 | 71.0 |
| 50 | 1900-10-27 | 1 | 5 | 9655 | 771 | 213.0 | 119.0 |
| 51 | 1900-11-10 | 1 | 5 | 10445 | 851 | NaN | NaN |
| 52 | 1900-11-02 | 0 | 4 | 8836 | 693 | 206.0 | 67.0 |
| 53 | 1900-10-20 | 1 | 5 | 10496 | 860 | 153.0 | 98.0 |
| 54 | 1900-10-17 | 1 | 2 | 9088 | 780 | 127.0 | 44.0 |
| 55 | 1900-11-05 | 1 | 0 | 9633 | 808 | NaN | NaN |
| 56 | 1900-11-09 | 1 | 4 | 9697 | 850 | NaN | NaN |
| 57 | 1900-10-15 | 0 | 0 | 10014 | 837 | 163.0 | 64.0 |
| 58 | 1900-10-20 | 0 | 5 | 10667 | 861 | 165.0 | 97.0 |
| 59 | 1900-11-11 | 1 | 6 | 9931 | 831 | NaN | NaN |
| 60 | 1900-10-19 | 0 | 4 | 8459 | 691 | 131.0 | 60.0 |
| 61 | 1900-10-22 | 1 | 0 | 9737 | 801 | 128.0 | 70.0 |
| 62 | 1900-10-11 | 1 | 3 | 7716 | 686 | 105.0 | 34.0 |
| 63 | 1900-10-13 | 0 | 5 | 10511 | 909 | 167.0 | 95.0 |
| 64 | 1900-11-14 | 1 | 2 | 9304 | 770 | NaN | NaN |
| 65 | 1900-11-16 | 1 | 4 | 8988 | 710 | NaN | NaN |
| 66 | 1900-11-04 | 1 | 6 | 9427 | 743 | NaN | NaN |
| 67 | 1900-10-31 | 0 | 2 | 8890 | 706 | 174.0 | 101.0 |
| 68 | 1900-10-23 | 1 | 1 | 8324 | 665 | 127.0 | 56.0 |
| 69 | 1900-11-11 | 1 | 6 | 9880 | 830 | NaN | NaN |
| 70 | 1900-10-24 | 1 | 2 | 9402 | 697 | 194.0 | 94.0 |
| 71 | 1900-10-18 | 0 | 3 | 7434 | 632 | 110.0 | 70.0 |
| 72 | 1900-10-26 | 0 | 4 | 8896 | 708 | 161.0 | 104.0 |
| 73 | 1900-11-06 | 1 | 1 | 9842 | 831 | NaN | NaN |
| 74 | 1900-10-14 | 0 | 6 | 9871 | 836 | 156.0 | 105.0 |
74 rows × 7 columns
data.head()
| row_id | Date | id | day_of_week | Pageviews | Clicks | Enrollments | Payments | |
|---|---|---|---|---|---|---|---|---|
| 28 | 1 | 1900-11-08 | 1 | 3 | 9010 | 756 | NaN | NaN |
| 10 | 2 | 1900-10-21 | 0 | 6 | 10660 | 867 | 196.0 | 105.0 |
| 72 | 3 | 1900-11-15 | 1 | 3 | 8668 | 724 | NaN | NaN |
| 40 | 4 | 1900-10-14 | 1 | 6 | 9867 | 827 | 138.0 | 92.0 |
| 6 | 5 | 1900-10-17 | 0 | 2 | 9008 | 748 | 146.0 | 76.0 |
As we can see from the result, interestingly all operations are successfull. day_of_week column indicateds 0 to 6 fro Monday to Sunday and id is for experment checking and row_id is used reference column.
#drop Date and Payments Coloumns
drop_coloumn_list = ['Date','Payments']
data=data.drop(drop_coloumn_list, axis=1)
data.shape
(74, 6)
##Handle the missing data (NA) by removing these rows
data = data.dropna(how='any',axis=0) #It will delete every row (axis=0) that has "any" Null value in it.
data.shape
(46, 6)
As we can see 28 rows are deleted because of missed values.
data.head(10)
| row_id | id | day_of_week | Pageviews | Clicks | Enrollments | |
|---|---|---|---|---|---|---|
| 10 | 2 | 0 | 6 | 10660 | 867 | 196.0 |
| 40 | 4 | 1 | 6 | 9867 | 827 | 138.0 |
| 6 | 5 | 0 | 2 | 9008 | 748 | 146.0 |
| 11 | 6 | 1 | 0 | 9947 | 838 | 162.0 |
| 1 | 9 | 0 | 4 | 9102 | 779 | 147.0 |
| 49 | 11 | 1 | 1 | 8176 | 642 | 122.0 |
| 5 | 13 | 1 | 1 | 9670 | 823 | 138.0 |
| 55 | 16 | 1 | 0 | 9262 | 727 | 201.0 |
| 56 | 18 | 1 | 1 | 9308 | 728 | 207.0 |
| 19 | 23 | 0 | 1 | 9345 | 734 | 167.0 |
Training Model
Three algorithms are compared. <ul><li>Random Forest</li><li>Decision Tree</li><li>XGBoost</li></ul>
from sklearn.ensemble import RandomForestRegressor
import xgboost as xgb
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import RandomizedSearchCV
from sklearn.metrics import auc, accuracy_score, confusion_matrix, mean_squared_error
from sklearn.model_selection import cross_val_score, GridSearchCV,StratifiedKFold, KFold, RandomizedSearchCV, train_test_split
def display_scores(scores):
print("Scores: {0}\nMean: {1:.3f}\nStd: {2:.3f}".format(scores, np.mean(scores), np.std(scores)))
def train_RandomForest(X_train, y_train):
scores = []
# Use the random grid to search for best hyperparameters
# Number of trees in random forest
n_estimators = [int(x) for x in np.linspace(start = 200, stop = 2000, num = 10)]
# Number of features to consider at every split
max_features = ['auto', 'sqrt']
# Maximum number of levels in tree
max_depth = [int(x) for x in np.linspace(10, 110, num = 11)]
max_depth.append(None)
# Minimum number of samples required to split a node
min_samples_split = [2, 5, 10]
# Minimum number of samples required at each leaf node
min_samples_leaf = [1, 2, 4]
# Method of selecting samples for training each tree
bootstrap = [True, False]
# Create the random grid
random_grid = {'n_estimators': n_estimators,
'max_features': max_features,
'max_depth': max_depth,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf,
'bootstrap': bootstrap}
# First create the base model to tune
rf = RandomForestRegressor()
# Random search of parameters, using 5 fold cross validation,
# search across 100 different combinations, and use all available cores
rf_random = RandomizedSearchCV(estimator = rf, param_distributions = random_grid, n_iter = 100, cv = 5,
verbose=1, random_state=42, n_jobs = -1)
# Fit the random search model
rf_random.fit(X_train, y_train)
predictions=rf_random.predict(y_train)
print("MSE:{0:.3f}\RMSE: {1:.3f}".format(mean_squared_error(y_test, predictions),
np.sqrt(mean_squared_error(y_train, predictions))))
def train_DT(X_train, y_train,x_test,y_test):
dtr= DecisionTreeRegressor()
dtr.fit(x_train,y_train)
y_pred = dtr.predict(x_test)
print(mean_squared_error(y_test, y_pred))
def train_XGB(X_train,X_test,y_train, y_test):
data_dmatrix = xgb.DMatrix(data=X_train,label=y_train)
params = {"objective":"reg:linear",'colsample_bytree': 0.3,'learning_rate': 0.1,
'max_depth': 5, 'alpha': 10}
cv_results = xgb.cv(dtrain=data_dmatrix, params=params, nfold=5,
num_boost_round=100,early_stopping_rounds=10,metrics="rmse", as_pandas=True, seed=123)
print(cv_results.head())
print((cv_results["test-rmse-mean"]).tail(1))
xg_reg = xgb.train(params=params, dtrain=data_dmatrix, num_boost_round=10)
xgb.plot_importance(xg_reg)
plt.rcParams['figure.figsize'] = [5, 5]
plt.show()
y=data.Enrollments.values
X=data.drop(['row_id','Enrollments'], axis=1)
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size = 0.1, random_state=42)
train_XGB(X_train,X_test,y_train, y_test)
train-rmse-mean train-rmse-std test-rmse-mean test-rmse-std
0 143.495904 1.871520 143.279126 8.566915
1 130.381508 1.717758 130.058894 8.708339
2 118.602792 1.583638 118.318460 8.869647
3 108.052387 1.467057 107.744661 9.012557
4 98.600679 1.365147 98.665820 9.160198
72 28.488258
Name: test-rmse-mean, dtype: float64
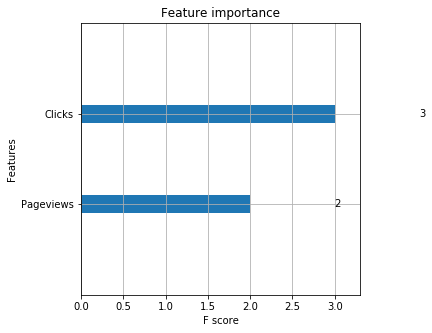
The information gain is 50% from Pageviews and Clicks combined. Experiment has no significan contribution to information gain, indicating it’s still predictive (just not nearly as much as Pageviews). This tells a story that if Enrollments are critical, Udacity should focus on getting clicks and Pageviews.
To generalize the result even if further investigation is required for other models also, If Udacity wants to maximimize enrollments, it should focus on getting clicks. Click is the most important feature in our model.
#train_DT(X_train, y_train,x_test,y_test)
#train_RandomForest(X,y)
Further investigation can be continued, but for now I have to stop because of deadline. Hope I will come up with further investigation.