
Amharic Character Recognition using Deep Neural Network
Objective
I will use a dataset consisting of Amharic digits (1-9). I will develop develop a deep, fully-connected (“feed-forward”) neural network model that can classify these images. In the process we will discuss:
- Data collection and preparation
- Implementing Deep feed forward Neural networks
- Libraries
- Reading Data with data generators
- Data augmentation
- Transfer Learning
import keras
from keras_preprocessing.image import ImageDataGenerator,array_to_img, img_to_array, load_img
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dropout, Dense, BatchNormalization, Activation
from keras.optimizers import RMSprop, SGD, Adam
from keras.losses import sparse_categorical_crossentropy
import matplotlib.pyplot as plt
import numpy as np
import os
from keras import models
import cv2
Data Generators
Motivation
Data preparation is required when working with neural network and deep learning models. Increasingly data augmentation is also required on more complex object recognition tasks.
Like the rest of Keras, the image augmentation API is simple and powerful.
Keras provides the ImageDataGenerator class that defines the configuration for image data preparation and augmentation. This includes capabilities such as:
- Sample-wise standardization.
- Feature-wise standardization.
- ZCA whitening.
- Random rotation, shifts, shear and flips.
- Dimension reordering.
- Save augmented images to disk.
## Using the ImageDataGenerator to: Provide a validation split of 20% of the data rescale the images, perform augmentation
datagen = ImageDataGenerator(validation_split=0.2,
rescale=1./255 ,
shear_range=0.2,
width_shift_range=0.2,
height_shift_range=0.2,
zoom_range=0.2,
fill_mode='nearest',
horizontal_flip=True)
### Specify directory containing amharic dataset
TRAIN_DIR = 'amharic'
## Use train generator to create train data from entire dataset
train_generator = datagen.flow_from_directory(
TRAIN_DIR,
subset='training',
target_size=(200, 200),
batch_size=32,
class_mode='categorical'
)
# use validation_generator to create dataset from 20% of the data
validation_generator = datagen.flow_from_directory(
TRAIN_DIR,
subset='validation',
target_size=(200, 200),
batch_size=32,
class_mode='categorical'
)
Found 95 images belonging to 9 classes.
Found 18 images belonging to 9 classes.
Data Description
Dataset consists of images of Amharic numbers mostly extracted from the internet. The Idea here is to train a machine learning model, specifically a deep convolutional neural network to learn to recognize the amharic numbers.
Data preparation
The images were rescaled to 200x200 px with the help of the data generators.
Note:
In this tutorial, the dataset was not standardized as in the MNIST dataset, an additional task is to use the lessons learnt from the computer vision class to standardize the dataset to have consistent backgrounds like that from the MNIST dataset.
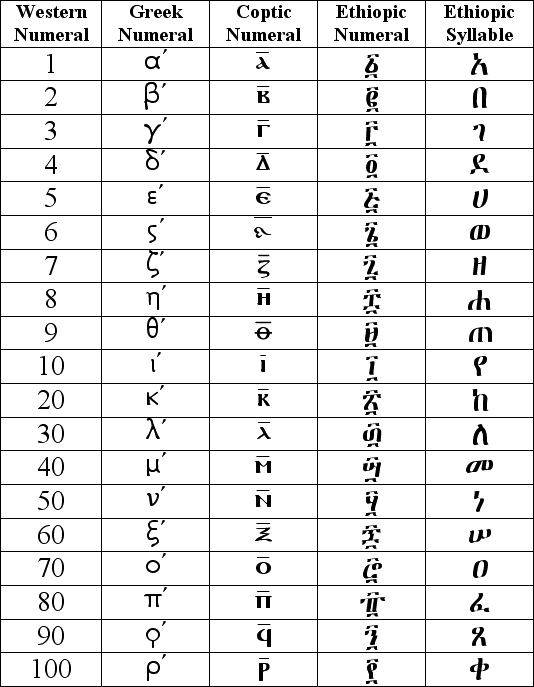
Amharic Number system
Ethiopic numerals have a familiar quality about them that seems to catch the eye and pique the imagination of the first-time viewer. In particular, the bars above and below the letter-like symbols appear reminiscent of their Roman counterparts. The symbols in between the bars, however, are clearly not of Roman origin. The shapes appear Ethiopic but only half seem to correspond to Ethiopic syllables and in an incomprehensible order.
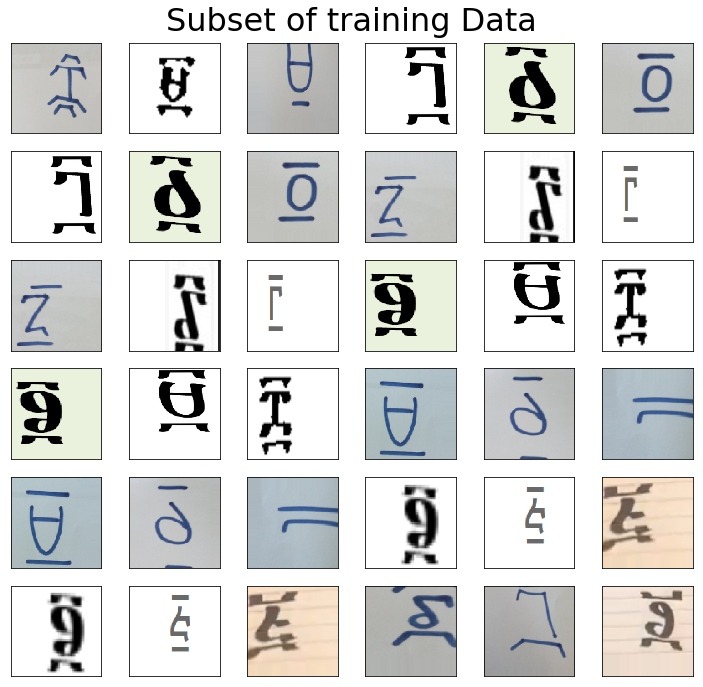
def plot_images(img_gen, img_title):
fig, ax = plt.subplots(6,6, figsize=(10,10))
plt.suptitle(img_title, size=32)
plt.setp(ax, xticks=[], yticks=[])
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
for (img, label) in img_gen:
for i in range(6):
for j in range(6):
if i*6 + j < 256:
ax[i][j].imshow(img[i*3 + j])
break
plot_images(train_generator, "Subset of training Data")
!mkdir preview
img = load_img('amharic/1/Annotation 2019-05-23 124618.png') # this is a PIL image
x = img_to_array(img) # this is a Numpy array with shape (3, 150, 150)
x = x.reshape((1,) + x.shape) # this is a Numpy array with shape (1, 3, 150, 150)
# the .flow() command below generates batches of randomly transformed images
# and saves the results to the `preview/` directory
i = 0
for batch in datagen.flow(x, batch_size=1,
save_to_dir='preview', save_prefix='cat', save_format='jpeg'):
i += 1
if i > 20:
break # otherwise the generator would loop indefinitely
Computer Vision
First we will cover non deep learning approaches used to pre-process and analyse images
1. Otsu Thresholding
Segment out the actual image
A technique used to create a binary image that can be used in a fully connected network model Create image resized to fit into a CNN
from skimage.filters import threshold_otsu
amharic = './amharic/3/Annotation 2019-05-23 125407.png'
img = cv2.imread(amharic)
imggray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
plt.imshow(img)
<matplotlib.image.AxesImage at 0x7eff53d8fc18>

# Get threshold from image
threshold_value = threshold_otsu(imggray)
img_background = imggray > threshold_value
bimage = img_background.astype(np.int)
bimage2 = img_background.astype(np.uint8)
plt.imshow(bimage2, cmap='gray')
<matplotlib.image.AxesImage at 0x7eff55fbd6d8>

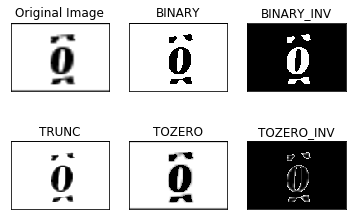
img = cv2.imread('amharic/4/Annotation 2019-05-23 125039.png',0)
ret,thresh1 = cv2.threshold(img,127,255,cv2.THRESH_BINARY)
ret,thresh2 = cv2.threshold(img,127,255,cv2.THRESH_BINARY_INV)
ret,thresh3 = cv2.threshold(img,127,255,cv2.THRESH_TRUNC)
ret,thresh4 = cv2.threshold(img,127,255,cv2.THRESH_TOZERO)
ret,thresh5 = cv2.threshold(img,127,255,cv2.THRESH_TOZERO_INV)
titles = ['Original Image','BINARY','BINARY_INV','TRUNC','TOZERO','TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in range(6):
plt.subplot(2,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
2. Edge Detection
img = cv2.imread('amharic/6/Annotation 2019-05-23 125918.png',0)
edges = cv2.Canny(img,100,200)
plt.subplot(121),plt.imshow(img,cmap = 'gray')
plt.title('Original Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(edges,cmap = 'gray')
plt.title('Edge Image'), plt.xticks([]), plt.yticks([])
plt.show()

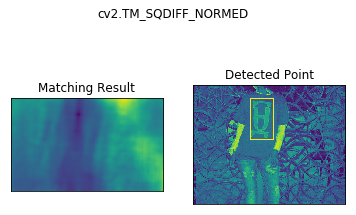
3. Template Matching
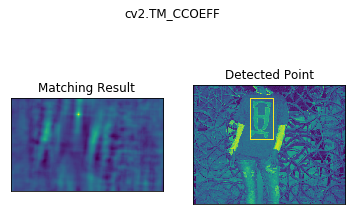
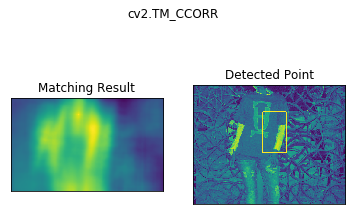
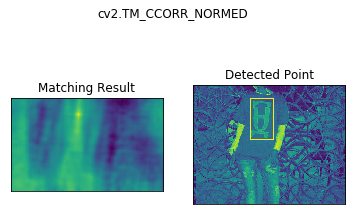
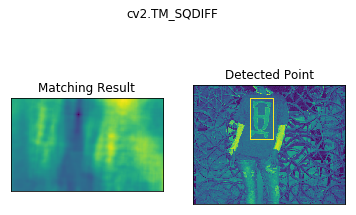
Template Matching is a method for searching and finding the location of a template image in a larger image. OpenCV comes with a function cv2.matchTemplate() for this purpose. It simply slides the template image over the input image (as in 2D convolution) and compares the template and patch of input image under the template image. Several comparison methods are implemented in OpenCV. (You can check docs for more details). It returns a grayscale image, where each pixel denotes how much does the neighbourhood of that pixel match with template.
3.1 Single Object template Matching
image = cv2.imread('geez_number.jpg')
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.title("Original Image")
plt.show()

template = cv2.imread('geez_template.jpg')
plt.imshow(cv2.cvtColor(template, cv2.COLOR_BGR2RGB))
plt.title("Template")
plt.show()

img = cv2.imread('geez_number.jpg',0)
img2 = img.copy()
template = cv2.imread('geez_template.jpg',0)
w, h = template.shape[::-1]
# All the 6 methods for comparison in a list
plt.imshow(img)
methods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR',
'cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED']
for meth in methods:
img = img2.copy()
method = eval(meth)
# Apply template Matching
res = cv2.matchTemplate(img,template,method)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# If the method is TM_SQDIFF or TM_SQDIFF_NORMED, take minimum
if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
cv2.rectangle(img,top_left, bottom_right, 255, 2)
plt.subplot(121),plt.imshow(res)
plt.title('Matching Result'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(img)
plt.title('Detected Point'), plt.xticks([]), plt.yticks([])
plt.suptitle(meth)
plt.show()

3.2 Multiple Object Template Matchin
image = cv2.imread('taxis.jpg')
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.title("Original Image")
plt.show()

template = cv2.imread('taxis_template_2.jpg')
plt.imshow(cv2.cvtColor(template, cv2.COLOR_BGR2RGB))
plt.title("Template")
plt.show()

img_rgb = cv2.imread('taxis.jpg')
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
template = cv2.imread('taxis_template_2.jpg',0)
w, h = template.shape[::-1]
res = cv2.matchTemplate(img_gray,template,cv2.TM_CCOEFF_NORMED)
threshold = 0.8
loc = np.where( res >= threshold)
for pt in zip(*loc[::-1]):
cv2.rectangle(img_rgb, pt, (pt[0] + w, pt[1] + h), (0,0,255), 2)
cv2.imwrite('res.png',img_rgb)
processed_image = plt.imread('res.png')
plt.title("Processed Image with matched templates")
plt.imshow(processed_image)
<matplotlib.image.AxesImage at 0x7eff55528668>

image = cv2.imread('taxis_2.jpg')
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
plt.title("Original Image")
plt.show()

template = cv2.imread('taxi_template.jpg')
plt.imshow(cv2.cvtColor(template, cv2.COLOR_BGR2RGB))
plt.title("Template")
plt.show()

img_rgb = cv2.imread('taxis_2.jpg')
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
template = cv2.imread('taxi_template.jpg',0)
w, h = template.shape[::-1]
res = cv2.matchTemplate(img_gray,template,cv2.TM_CCOEFF_NORMED)
threshold = 0.8
loc = np.where( res >= threshold)
for pt in zip(*loc[::-1]):
cv2.rectangle(img_rgb, pt, (pt[0] + w, pt[1] + h), (0,0,255), 2)
cv2.imwrite('res2.png',img_rgb)
processed_image = plt.imread('res2.png')
plt.title("Processed Image with matched templates")
plt.imshow(processed_image)
<matplotlib.image.AxesImage at 0x7eff55490860>

Convolutional Neural Nets with Keras Sequential API
There are two ways to build Keras models: sequential and functional.
The sequential API allows you to create models layer-by-layer for most problems. It is limited in that it does not allow you to create models that share layers or have multiple inputs or outputs.
Alternatively, the functional API allows you to create models that have a lot more flexibility as you can easily define models where layers connect to more than just the previous and next layers. In fact, you can connect layers to (literally) any other layer. As a result, creating complex networks such as siamese networks and residual networks become possible.
Steps Involved
- Initialize Sequential Model
- Add layers (conv, Pooling, Dense, flatten etc)
- Compile Model (Loss function, optimizer, metrics)
- Fit Model (Means to train the model)
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(200, 200, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten()) # this converts our 3D feature maps to 1D feature vectors
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(9))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
WARNING:tensorflow:From c:\users\user\appdata\local\programs\python\python36\lib\site-packages\tensorflow\python\framework\op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
WARNING:tensorflow:From c:\users\user\appdata\local\programs\python\python36\lib\site-packages\keras\backend\tensorflow_backend.py:3445: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.
Instructions for updating:
Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 198, 198, 32) 896
_________________________________________________________________
activation_1 (Activation) (None, 198, 198, 32) 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 99, 99, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 97, 97, 32) 9248
_________________________________________________________________
activation_2 (Activation) (None, 97, 97, 32) 0
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 48, 48, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 46, 46, 64) 18496
_________________________________________________________________
activation_3 (Activation) (None, 46, 46, 64) 0
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 23, 23, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 33856) 0
_________________________________________________________________
dense_1 (Dense) (None, 64) 2166848
_________________________________________________________________
activation_4 (Activation) (None, 64) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 64) 0
_________________________________________________________________
dense_2 (Dense) (None, 9) 585
_________________________________________________________________
activation_5 (Activation) (None, 9) 0
=================================================================
Total params: 2,196,073
Trainable params: 2,196,073
Non-trainable params: 0
_________________________________________________________________
batch_size = 16
history = model.fit_generator(
train_generator,
steps_per_epoch=2000 // batch_size,
epochs=50,
validation_data=validation_generator,
validation_steps=800 // batch_size)
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
Epoch 1/50
125/125 [==============================] - 46s 364ms/step - loss: 2.2660 - acc: 0.1270 - val_loss: 2.1976 - val_acc: 0.1056
Epoch 2/50
125/125 [==============================] - 38s 307ms/step - loss: 2.1230 - acc: 0.1800 - val_loss: 2.1956 - val_acc: 0.1233
Epoch 3/50
125/125 [==============================] - 40s 320ms/step - loss: 2.0463 - acc: 0.2182 - val_loss: 2.1697 - val_acc: 0.1422
Epoch 4/50
125/125 [==============================] - 40s 323ms/step - loss: 1.9005 - acc: 0.2925 - val_loss: 2.1469 - val_acc: 0.1911
Epoch 5/50
125/125 [==============================] - 40s 319ms/step - loss: 1.7748 - acc: 0.3444 - val_loss: 2.0834 - val_acc: 0.2144
Epoch 6/50
125/125 [==============================] - 39s 308ms/step - loss: 1.6230 - acc: 0.4071 - val_loss: 2.0261 - val_acc: 0.2900
Epoch 7/50
125/125 [==============================] - 40s 316ms/step - loss: 1.5100 - acc: 0.4432 - val_loss: 1.9231 - val_acc: 0.3133
Epoch 8/50
125/125 [==============================] - 39s 314ms/step - loss: 1.4584 - acc: 0.4799 - val_loss: 1.8885 - val_acc: 0.3733
Epoch 9/50
125/125 [==============================] - 40s 317ms/step - loss: 1.3437 - acc: 0.5039 - val_loss: 1.8675 - val_acc: 0.3733
Epoch 10/50
125/125 [==============================] - 39s 309ms/step - loss: 1.2557 - acc: 0.5459 - val_loss: 1.7921 - val_acc: 0.4344
Epoch 11/50
125/125 [==============================] - 40s 317ms/step - loss: 1.1758 - acc: 0.5763 - val_loss: 1.6952 - val_acc: 0.4633
Epoch 12/50
125/125 [==============================] - 40s 319ms/step - loss: 1.1045 - acc: 0.6046 - val_loss: 1.7389 - val_acc: 0.4133
Epoch 13/50
125/125 [==============================] - 40s 318ms/step - loss: 1.0729 - acc: 0.6208 - val_loss: 1.6569 - val_acc: 0.4433
Epoch 14/50
125/125 [==============================] - 38s 307ms/step - loss: 1.0311 - acc: 0.6303 - val_loss: 1.7715 - val_acc: 0.4367
Epoch 15/50
125/125 [==============================] - 39s 316ms/step - loss: 1.0009 - acc: 0.6586 - val_loss: 1.7016 - val_acc: 0.4400
Epoch 16/50
125/125 [==============================] - 39s 312ms/step - loss: 0.9397 - acc: 0.6572 - val_loss: 1.8776 - val_acc: 0.3967
Epoch 17/50
125/125 [==============================] - 39s 315ms/step - loss: 0.8857 - acc: 0.6751 - val_loss: 1.3812 - val_acc: 0.5711
Epoch 18/50
125/125 [==============================] - 38s 306ms/step - loss: 0.8698 - acc: 0.6816 - val_loss: 1.6375 - val_acc: 0.4356
Epoch 19/50
125/125 [==============================] - 40s 317ms/step - loss: 0.8408 - acc: 0.6936 - val_loss: 1.3586 - val_acc: 0.6022
Epoch 20/50
125/125 [==============================] - 40s 320ms/step - loss: 0.8060 - acc: 0.7142 - val_loss: 1.4839 - val_acc: 0.5189
Epoch 21/50
125/125 [==============================] - 40s 317ms/step - loss: 0.8351 - acc: 0.7056 - val_loss: 1.4856 - val_acc: 0.5456
Epoch 22/50
125/125 [==============================] - 39s 310ms/step - loss: 0.7839 - acc: 0.7221 - val_loss: 1.4683 - val_acc: 0.5267
Epoch 23/50
125/125 [==============================] - 40s 324ms/step - loss: 0.8305 - acc: 0.7068 - val_loss: 1.6215 - val_acc: 0.5400
Epoch 24/50
125/125 [==============================] - 39s 311ms/step - loss: 0.8091 - acc: 0.7103 - val_loss: 1.2579 - val_acc: 0.6056
Epoch 25/50
125/125 [==============================] - 40s 319ms/step - loss: 0.7652 - acc: 0.7254 - val_loss: 1.3563 - val_acc: 0.5900
Epoch 26/50
125/125 [==============================] - 38s 307ms/step - loss: 0.7794 - acc: 0.7317 - val_loss: 1.3431 - val_acc: 0.5678
Epoch 27/50
125/125 [==============================] - 40s 318ms/step - loss: 0.7555 - acc: 0.7339 - val_loss: 1.3445 - val_acc: 0.5411
Epoch 28/50
125/125 [==============================] - 40s 318ms/step - loss: 0.7213 - acc: 0.7377 - val_loss: 1.1485 - val_acc: 0.6233
Epoch 29/50
125/125 [==============================] - 40s 317ms/step - loss: 0.8154 - acc: 0.7360 - val_loss: 1.2860 - val_acc: 0.5756
Epoch 30/50
125/125 [==============================] - 39s 310ms/step - loss: 0.7235 - acc: 0.7475 - val_loss: 1.3299 - val_acc: 0.5511
Epoch 31/50
125/125 [==============================] - 40s 319ms/step - loss: 0.7306 - acc: 0.7512 - val_loss: 1.3363 - val_acc: 0.5322
Epoch 32/50
125/125 [==============================] - 39s 310ms/step - loss: 0.7316 - acc: 0.7366 - val_loss: 1.1590 - val_acc: 0.5967
Epoch 33/50
125/125 [==============================] - 40s 318ms/step - loss: 0.6847 - acc: 0.7602 - val_loss: 1.2039 - val_acc: 0.6100
Epoch 34/50
125/125 [==============================] - 39s 309ms/step - loss: 0.7102 - acc: 0.7595 - val_loss: 1.3023 - val_acc: 0.5844
Epoch 35/50
125/125 [==============================] - 40s 322ms/step - loss: 0.7061 - acc: 0.7554 - val_loss: 1.2237 - val_acc: 0.6267
Epoch 36/50
125/125 [==============================] - 39s 313ms/step - loss: 0.7030 - acc: 0.7627 - val_loss: 1.1402 - val_acc: 0.6189
Epoch 37/50
125/125 [==============================] - 40s 317ms/step - loss: 0.7481 - acc: 0.7491 - val_loss: 1.3752 - val_acc: 0.5700
Epoch 38/50
125/125 [==============================] - 38s 308ms/step - loss: 0.6787 - acc: 0.7682 - val_loss: 1.2422 - val_acc: 0.5700
Epoch 39/50
125/125 [==============================] - 41s 324ms/step - loss: 0.6983 - acc: 0.7658 - val_loss: 2.5488 - val_acc: 0.4489
Epoch 40/50
125/125 [==============================] - 39s 310ms/step - loss: 0.7723 - acc: 0.7416 - val_loss: 1.2494 - val_acc: 0.5878
Epoch 41/50
125/125 [==============================] - 40s 317ms/step - loss: 0.7114 - acc: 0.7622 - val_loss: 1.3310 - val_acc: 0.6000
Epoch 42/50
125/125 [==============================] - 39s 311ms/step - loss: 0.7846 - acc: 0.7534 - val_loss: 1.1058 - val_acc: 0.6311
Epoch 43/50
125/125 [==============================] - 40s 319ms/step - loss: 0.6706 - acc: 0.7705 - val_loss: 1.3311 - val_acc: 0.5244
Epoch 44/50
125/125 [==============================] - 39s 311ms/step - loss: 0.6820 - acc: 0.7644 - val_loss: 1.2269 - val_acc: 0.5822
Epoch 45/50
125/125 [==============================] - 39s 311ms/step - loss: 0.6934 - acc: 0.7656 - val_loss: 1.4280 - val_acc: 0.5600
Epoch 46/50
125/125 [==============================] - 39s 313ms/step - loss: 0.6762 - acc: 0.7698 - val_loss: 1.2354 - val_acc: 0.6667
Epoch 47/50
125/125 [==============================] - 39s 315ms/step - loss: 0.6923 - acc: 0.7718 - val_loss: 1.2367 - val_acc: 0.6311
Epoch 48/50
125/125 [==============================] - 39s 314ms/step - loss: 0.7104 - acc: 0.7611 - val_loss: 1.1435 - val_acc: 0.6156
Epoch 49/50
125/125 [==============================] - 38s 305ms/step - loss: 0.6568 - acc: 0.7828 - val_loss: 1.1379 - val_acc: 0.6322
Epoch 50/50
125/125 [==============================] - 39s 316ms/step - loss: 0.7349 - acc: 0.7598 - val_loss: 0.9543 - val_acc: 0.7189
### Save weights
model.save_weights('first.h5')
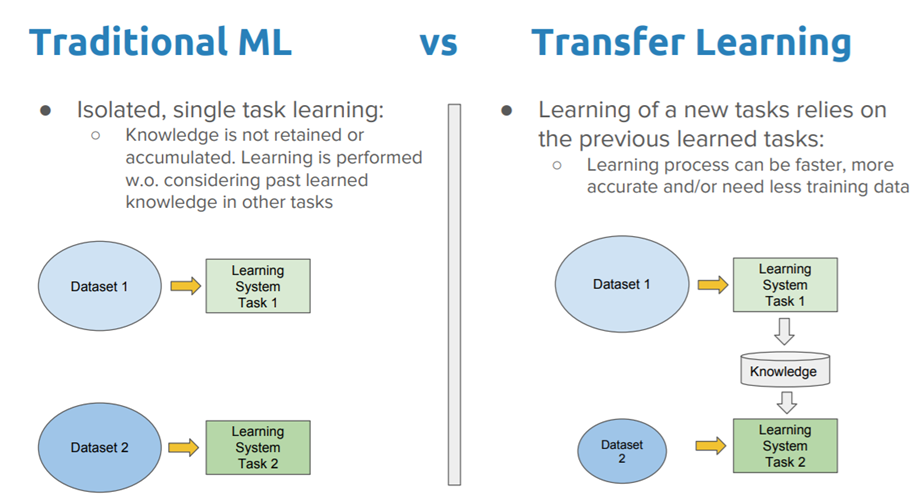
Transfer Learning
Transfer learning is a machine learning technique where a model trained on one task is re-purposed on a second related task.
Transfer Learning with Image Data
It is common to perform transfer learning with predictive modeling problems that use image data as input.
This may be a prediction task that takes photographs or video data as input.
For these types of problems, it is common to use a deep learning model pre-trained for a large and challenging image classification task such as the ImageNet 1000-class photograph classification competition.
The research organizations that develop models for this competition and do well often release their final model under a permissive license for reuse. These models can take days or weeks to train on modern hardware.
These models can be downloaded and incorporated directly into new models that expect image data as input.
from keras.applications import VGG16
VGG 16

# Use imagenet weights
vgg_conv = VGG16(weights='imagenet',
include_top = False,
input_shape = (200,200,3))
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
Downloading data from https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5
58892288/58889256 [==============================] - 4s 0us/step
vgg_conv.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, 200, 200, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 200, 200, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 200, 200, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 100, 100, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 100, 100, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 100, 100, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 50, 50, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 50, 50, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 50, 50, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 50, 50, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 25, 25, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 25, 25, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 25, 25, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 25, 25, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 12, 12, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 12, 12, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 12, 12, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 12, 12, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 6, 6, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________
### Add our custom laters
tr_model = vgg_conv.output
tr_model = Flatten()(tr_model)
tr_model = Dense(64, activation='relu')(tr_model)
tr_model = Dropout(0.5)(tr_model)
tr_model = Dense(9, activation='softmax')(tr_model)
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py:3445: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.
Instructions for updating:
Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.
new_model = models.Model(inputs=vgg_conv.input, outputs=tr_model)
Freezing and Fine-tuning vgg16

def print_layer_trainable():
for layer in new_model.layers:
print("{0}:\t{1}".format(layer.trainable, layer.name))
for i, layer in enumerate(new_model.layers):
print(i, layer.name)
0 input_2
1 block1_conv1
2 block1_conv2
3 block1_pool
4 block2_conv1
5 block2_conv2
6 block2_pool
7 block3_conv1
8 block3_conv2
9 block3_conv3
10 block3_pool
11 block4_conv1
12 block4_conv2
13 block4_conv3
14 block4_pool
15 block5_conv1
16 block5_conv2
17 block5_conv3
18 block5_pool
19 flatten_2
20 dense_3
21 dropout_2
22 dense_4
for layer in new_model.layers[:18]:
layer.trainable = False
for layer in new_model.layers[18:]:
layer.trainable = True
print_layer_trainable()
False: input_2
False: block1_conv1
False: block1_conv2
False: block1_pool
False: block2_conv1
False: block2_conv2
False: block2_pool
False: block3_conv1
False: block3_conv2
False: block3_conv3
False: block3_pool
False: block4_conv1
False: block4_conv2
False: block4_conv3
False: block4_pool
False: block5_conv1
False: block5_conv2
False: block5_conv3
True: block5_pool
True: flatten_2
True: dense_3
True: dropout_2
True: dense_4
new_model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
history = new_model.fit_generator(
train_generator,
steps_per_epoch=2000 // batch_size,
epochs=50,
validation_data=validation_generator,
validation_steps=800 // batch_size)
Epoch 1/50
125/125 [==============================] - 49s 391ms/step - loss: 2.2662 - acc: 0.1765 - val_loss: 1.9555 - val_acc: 0.2978
Epoch 2/50
125/125 [==============================] - 43s 348ms/step - loss: 1.8748 - acc: 0.2395 - val_loss: 1.6836 - val_acc: 0.4144
Epoch 3/50
125/125 [==============================] - 42s 337ms/step - loss: 1.6959 - acc: 0.3216 - val_loss: 1.4831 - val_acc: 0.4722
Epoch 4/50
125/125 [==============================] - 43s 348ms/step - loss: 1.5186 - acc: 0.4015 - val_loss: 1.2469 - val_acc: 0.5578
Epoch 5/50
125/125 [==============================] - 44s 353ms/step - loss: 1.2423 - acc: 0.5065 - val_loss: 1.0319 - val_acc: 0.7711
Epoch 6/50
125/125 [==============================] - 43s 343ms/step - loss: 1.0721 - acc: 0.5712 - val_loss: 0.8763 - val_acc: 0.7200
Epoch 7/50
125/125 [==============================] - 43s 345ms/step - loss: 0.9445 - acc: 0.6178 - val_loss: 0.6730 - val_acc: 0.7922
Epoch 8/50
125/125 [==============================] - 43s 342ms/step - loss: 0.8673 - acc: 0.6464 - val_loss: 0.5820 - val_acc: 0.8667
Epoch 9/50
125/125 [==============================] - 43s 346ms/step - loss: 0.8263 - acc: 0.6709 - val_loss: 0.5039 - val_acc: 0.8589
Epoch 10/50
125/125 [==============================] - 42s 336ms/step - loss: 0.7714 - acc: 0.6927 - val_loss: 0.5687 - val_acc: 0.9133
Epoch 11/50
125/125 [==============================] - 43s 344ms/step - loss: 0.7339 - acc: 0.7027 - val_loss: 0.4528 - val_acc: 0.8756
Epoch 12/50
125/125 [==============================] - 43s 346ms/step - loss: 0.7018 - acc: 0.7331 - val_loss: 0.4825 - val_acc: 0.8922
Epoch 13/50
125/125 [==============================] - 43s 343ms/step - loss: 0.7131 - acc: 0.7278 - val_loss: 0.4079 - val_acc: 0.8878
Epoch 14/50
125/125 [==============================] - 42s 335ms/step - loss: 0.6805 - acc: 0.7386 - val_loss: 0.3441 - val_acc: 0.9278
Epoch 15/50
125/125 [==============================] - 43s 345ms/step - loss: 0.6588 - acc: 0.7418 - val_loss: 0.3927 - val_acc: 0.9033
Epoch 16/50
125/125 [==============================] - 42s 334ms/step - loss: 0.6528 - acc: 0.7466 - val_loss: 0.3433 - val_acc: 0.9100
Epoch 17/50
125/125 [==============================] - 43s 344ms/step - loss: 0.6405 - acc: 0.7541 - val_loss: 0.3574 - val_acc: 0.8756
Epoch 18/50
125/125 [==============================] - 42s 332ms/step - loss: 0.6267 - acc: 0.7567 - val_loss: 0.5040 - val_acc: 0.8456
Epoch 19/50
125/125 [==============================] - 44s 354ms/step - loss: 0.6169 - acc: 0.7621 - val_loss: 0.4060 - val_acc: 0.8556
Epoch 20/50
125/125 [==============================] - 42s 338ms/step - loss: 0.5923 - acc: 0.7749 - val_loss: 0.4408 - val_acc: 0.8989
Epoch 21/50
125/125 [==============================] - 43s 346ms/step - loss: 0.6054 - acc: 0.7632 - val_loss: 0.3231 - val_acc: 0.9033
Epoch 22/50
125/125 [==============================] - 44s 350ms/step - loss: 0.5647 - acc: 0.7838 - val_loss: 0.3578 - val_acc: 0.8911
Epoch 23/50
125/125 [==============================] - 42s 338ms/step - loss: 0.5438 - acc: 0.7911 - val_loss: 0.1968 - val_acc: 0.9500
Epoch 24/50
125/125 [==============================] - 43s 347ms/step - loss: 0.5381 - acc: 0.7887 - val_loss: 0.2241 - val_acc: 0.9411
Epoch 25/50
125/125 [==============================] - 42s 337ms/step - loss: 0.5093 - acc: 0.7991 - val_loss: 0.2531 - val_acc: 0.9278
Epoch 26/50
125/125 [==============================] - 43s 346ms/step - loss: 0.4970 - acc: 0.8086 - val_loss: 0.2138 - val_acc: 0.9567
Epoch 27/50
125/125 [==============================] - 43s 346ms/step - loss: 0.4922 - acc: 0.8084 - val_loss: 0.3187 - val_acc: 0.9200
Epoch 28/50
125/125 [==============================] - 43s 345ms/step - loss: 0.4746 - acc: 0.8239 - val_loss: 0.4983 - val_acc: 0.8711
Epoch 29/50
125/125 [==============================] - 42s 339ms/step - loss: 0.4408 - acc: 0.8281 - val_loss: 0.4270 - val_acc: 0.8800
Epoch 30/50
125/125 [==============================] - 43s 345ms/step - loss: 0.4710 - acc: 0.8202 - val_loss: 0.2943 - val_acc: 0.9089
Epoch 31/50
125/125 [==============================] - 42s 337ms/step - loss: 0.4598 - acc: 0.8168 - val_loss: 0.3496 - val_acc: 0.8989
Epoch 32/50
125/125 [==============================] - 43s 345ms/step - loss: 0.4529 - acc: 0.8266 - val_loss: 0.2500 - val_acc: 0.9400
Epoch 33/50
125/125 [==============================] - 42s 337ms/step - loss: 0.4361 - acc: 0.8348 - val_loss: 0.2828 - val_acc: 0.9356
Epoch 34/50
125/125 [==============================] - 44s 355ms/step - loss: 0.4467 - acc: 0.8282 - val_loss: 0.3925 - val_acc: 0.9078
Epoch 35/50
125/125 [==============================] - 42s 337ms/step - loss: 0.4598 - acc: 0.8197 - val_loss: 0.5981 - val_acc: 0.8478
Epoch 36/50
125/125 [==============================] - 44s 351ms/step - loss: 0.4366 - acc: 0.8323 - val_loss: 0.2859 - val_acc: 0.9333
Epoch 37/50
125/125 [==============================] - 43s 344ms/step - loss: 0.4636 - acc: 0.8219 - val_loss: 0.3378 - val_acc: 0.9167
Epoch 38/50
125/125 [==============================] - 42s 339ms/step - loss: 0.4873 - acc: 0.8204 - val_loss: 0.3408 - val_acc: 0.9122
Epoch 39/50
125/125 [==============================] - 43s 347ms/step - loss: 0.4422 - acc: 0.8336 - val_loss: 0.4412 - val_acc: 0.9133
Epoch 40/50
125/125 [==============================] - 42s 337ms/step - loss: 0.4416 - acc: 0.8290 - val_loss: 0.3737 - val_acc: 0.9078
Epoch 41/50
125/125 [==============================] - 44s 349ms/step - loss: 0.4314 - acc: 0.8337 - val_loss: 0.4530 - val_acc: 0.8633
Epoch 42/50
125/125 [==============================] - 42s 337ms/step - loss: 0.4149 - acc: 0.8423 - val_loss: 0.3574 - val_acc: 0.9011
Epoch 43/50
125/125 [==============================] - 44s 353ms/step - loss: 0.4534 - acc: 0.8290 - val_loss: 0.3258 - val_acc: 0.9178
Epoch 44/50
125/125 [==============================] - 42s 336ms/step - loss: 0.4423 - acc: 0.8307 - val_loss: 0.3778 - val_acc: 0.9067
Epoch 45/50
125/125 [==============================] - 43s 347ms/step - loss: 0.4176 - acc: 0.8374 - val_loss: 0.3783 - val_acc: 0.8933
Epoch 46/50
125/125 [==============================] - 42s 338ms/step - loss: 0.4086 - acc: 0.8394 - val_loss: 0.3790 - val_acc: 0.9022
Epoch 47/50
125/125 [==============================] - 43s 347ms/step - loss: 0.4120 - acc: 0.8376 - val_loss: 0.5045 - val_acc: 0.8678
Epoch 48/50
125/125 [==============================] - 44s 348ms/step - loss: 0.4341 - acc: 0.8314 - val_loss: 0.2613 - val_acc: 0.9144
Epoch 49/50
125/125 [==============================] - 43s 346ms/step - loss: 0.4405 - acc: 0.8280 - val_loss: 0.5647 - val_acc: 0.8856
Epoch 50/50
125/125 [==============================] - 42s 338ms/step - loss: 0.4096 - acc: 0.8408 - val_loss: 0.4827 - val_acc: 0.9089
new_model.save('transfer_model.h5')
from keras.models import load_model
new_model = load_model('transfer_model.h5')
WARNING:tensorflow:From c:\users\user\appdata\local\programs\python\python36\lib\site-packages\tensorflow\python\ops\math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
Visualization
test_files = validation_generator.filenames
def get_test_batch(root_path,img_paths):
return np.array([cv2.resize(cv2.imread(os.path.join(root_path,t)),(200,200)) for t in img_paths]), np.array([l.split("\\")[0] for l in img_paths])
batch, labels = get_test_batch(TRAIN_DIR, test_files)
preds = new_model.predict_on_batch(batch)
plt.figure(figsize=(15,100))
count = 1
for img,orig_img in zip(preds,batch):
plt.subplot(batch.shape[0],2,count)
plt.imshow(orig_img)
plt.xlabel('Original class: {},\n Predicted class: {}, \n Confidence: {:.4f}'.format(
labels[count-1],
np.argmax(img)+1,
img[np.argmax(img)]), fontsize=20)
plt.tight_layout()
count+=1
